Overview
Search relevance refers to the measure of how well search results align with the user's intent or query. In industries where vast amounts of information are available, such as e-commerce, content platforms, or news outlets, search relevance plays a crucial role in enhancing user experience and driving user engagement. It ensures that users can quickly and accurately find the information they are looking for.
Here are a few examples of industries where search relevance is essential:
-
E-commerce: In online shopping platforms like Amazon or eBay, search relevance is critical to help users find the products they want. Effective search algorithms consider various factors, such as product attributes, user preferences, and past behavior, to deliver relevant search results.
-
Content Platforms: Platforms like YouTube or Netflix rely on search relevance to recommend relevant videos or movies to users. The algorithms take into account user preferences, viewing history, and metadata analysis to provide personalized recommendations.
-
News Articles: In the context of news articles, search relevance is crucial to help users find relevant news stories quickly. As news outlets publish a large number of articles daily, users often rely on search functionality to discover articles related to specific topics, events, or keywords. By improving search relevancy, users can receive more accurate and timely news articles tailored to their interests.
For instance, consider a user searching for news articles about "climate change." A search system with high relevance would prioritize and display recent articles from credible sources that specifically discuss climate change, rather than articles unrelated to the topic or from less reputable sources. This ensures users can access the most relevant and trustworthy information on the subject they are interested in.
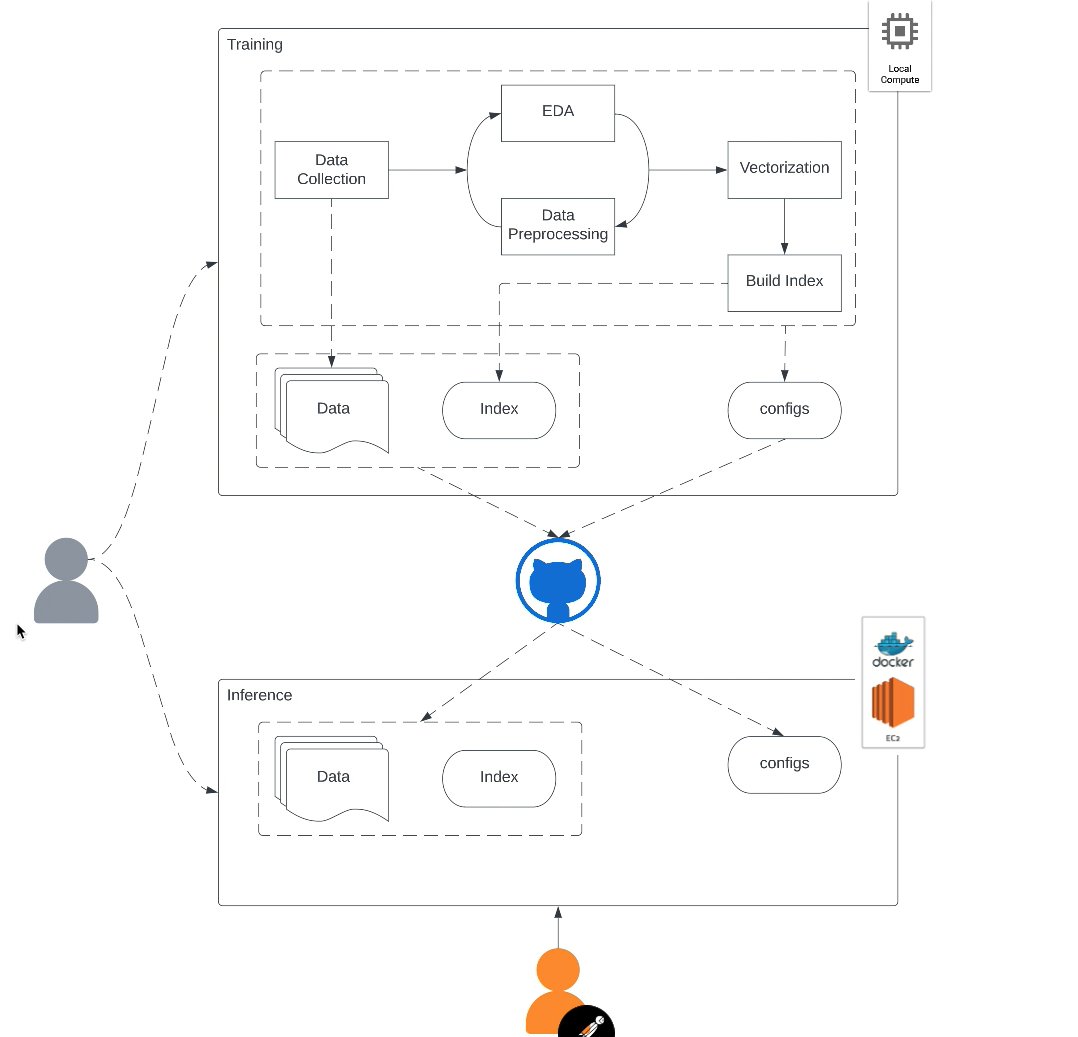
This project involves three key steps. Firstly, the Sentence-BERT (SBERT) model encodes news articles into semantically meaningful sentence embeddings. SBERT captures the contextual and semantic information of the articles, enabling more accurate representation and comparison. Secondly, the ANNOY library is utilized to create an index of the SBERT embeddings. ANNOY facilitates efficient approximate nearest neighbor search, enabling fast retrieval of similar articles based on cosine similarity scores. Lastly, the project is deployed on AWS using Docker containers, with a Flask API serving as the interface for users to interact with the system. The Flask API allows users to submit search queries and receive relevant news articles as search results, providing an intuitive and scalable solution.
Aim
This project aims to improve the search experience for news articles by leveraging the Sentence-BERT (SBERT) model and the ANNOY approximate nearest neighbor library. The project will be deployed on AWS using Docker containers and exposed as a Flask API, allowing users to query and retrieve relevant news articles easily.
Data Description
The dataset consists 22399 articles with the following attributes:
article_id: A unique identifier for each article in the dataset.
category: The broad category to which the article belongs, providing a high-level classification of the content.
subcategory: A more specific classification within the category, providing additional granularity to the article's topic.
title: The title or headline of the news article, summarizing the main subject or event.
published date: The date when the article was published or made available to the public.
text: The main body of the news article, containing the detailed information and context.
source: The source or publication from which the article originated.
Tech Stack
Language: Python
Libraries: pandas, numpy, spacy, sentence transformers, annoy, flask, AWS
Approach
Data Preprocessing:
Clean and preprocess the news article dataset, including tokenization, removal of stop words, and normalization.
SBERT Training:
Train the Sentence-BERT (SBERT) model using the preprocessed news articles to generate semantically meaningful sentence embeddings.
ANNOY Indexing:
Utilize the ANNOY library to create an index of the SBERT embeddings, enabling fast and efficient approximate nearest neighbor search.
Deployment on AWS with Docker:
Containerize the project components, including the Flask API, SBERT model, and ANNOY index, using Docker.
Deploy the Docker containers on AWS EC2 Instance.
![]()
MLOps SBERT